Languages can be fun, but they usually take a lot of time and effort to learn. Even if you put in the hours, some seem impossible to master. I for one can’t even make it past basic-level Korean, it seems, and my efforts to try to teach foreign friends to pronounce the Dutch ‘G’ have been hilarious, but also a bit painful to hear.
The Japanese script is one of the more complex ones in existence. In the ancient past, Japan did not have its own script and therefore Japanese scholars wrote in Chinese. At the same time, a lot of Chinese loanwords entered the Japanese language. Based on the Chinese ideographs, however, the Japanese also developed its own two syllabaries, two sets of written symbols which allowed them to write ‘real’ Japanese (as it was spoken) as opposed to Chinese (which was only a written language in Japan).

Even now, the Japanese script consists of three elements: Kanji (Chinese ideographs), hiragana (syllabary for Japanese words) and katakana (syllabary for foreign words). A lot of words can actually be written with any of these scripts: for example, the word hayashi (forest) can written in any of these scripts. In addition, the ideograph of hayashi can also be pronounced as rin!
A normal sentence usually has a mix of these three scripts:

And this is just Japanese 101. I could go on and on like this, but let’s get back to this site’s main focus: crime! Having three scripts (plus the Western alphabet and numerals) offers people a wide range of possibilities to write down their messages. And ever since the first original Japanese detective story, Edogawa Rampo’s “The Two-sen Copper Coin”, codes and the like have been quite popular in Japanese crime fiction. I will take a look at some of the more popular uses of the Japanese language as a sort of ‘code’ in crime fiction.
1) Double Readings
As shown in the ‘forest’ example, Japanese are used to using different kind of scripts to write things down. This is often used as a kind of code in crime fiction. I won’t spoil any stories, but for example, in real life, a popular abbreviation on the net for the Japanese yoroshiku (‘if it suits you/please’, but used in an extremely wide range of situations) is 4649. Why? Because this can be read as yottsu (four), roku (six), yottsu (four), ku (nine). Take the first syllables and what do we get? Exactly, yoroshiku. To make it more crime-fiction-esque, a simple code like 38336 could mean miyasan miro (look at Miya!), which could be rather damning evidence if you happened to be that Miya.
A rather old, but hilarious Japanese Fanta commercial also plays with this. Coming at 1:30, the teacher comes up with an utterly impossible string of Chinese ideographs (literally, it would be something like spitting-dew-not-hunting-old-depression). However, by choosing certain readings for certain characters, it’s read as to-ro-pi-karu furu-utsu, or pronounced more fluently, tropical fruits.
It’s not uncommon to see strings of seemingly meaningless characters in detective fiction that turn out to be hidden messages meant to be read in a different way.

2) Changing Messages
A popular trope in detective fiction is the dying clue. A victim tries to convey the name of his murderer just before he dies. The problem with Japanese ideographs is that many of them look alike. If a murderer discovers the message before the police do, he can change its meaning with very small additions. For example, let’s suppose a dying man tries to write the family name of his murderer, Takagi.

3. Too many scripts
And finally, a very popular trope in detective fiction: not knowing what script a message is written in! For example, what does this mean?
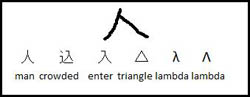
Is it the ideograph for ‘man’? Or is it an incomplete ideograph for ‘to be crowded’? Or maybe it’s not even a character, but an incomplete triangle? Or what about the Greek alphabet? With so many scripts used in Japanese, it’s often not clear how some characters are supposed to be read.
Japanese script has always been a big part of Japanese crime fiction and I doubt it will ever change. Even though some scholars do advocate an easier Japanese script, as it is quite time-consuming to master even for native speakers, no real change seems imminent in the near future. And I certainly wouldn’t like to see these creative ways to use the Japanese script in crime fiction disappear. These wordplay is neigh on impossible to translate to English or other Western languages, but few elements in Japanese crime fiction can be considered as culturally defined as the use of the Japanese script.